[WAPT Wk 1] NATAS Wargames Walkthrough
This post is meant to serve as a guide for our WAPT module’s week 1 practical exercise. Please do not plagiarize the contents of this post 🙏
Level 0 and 1
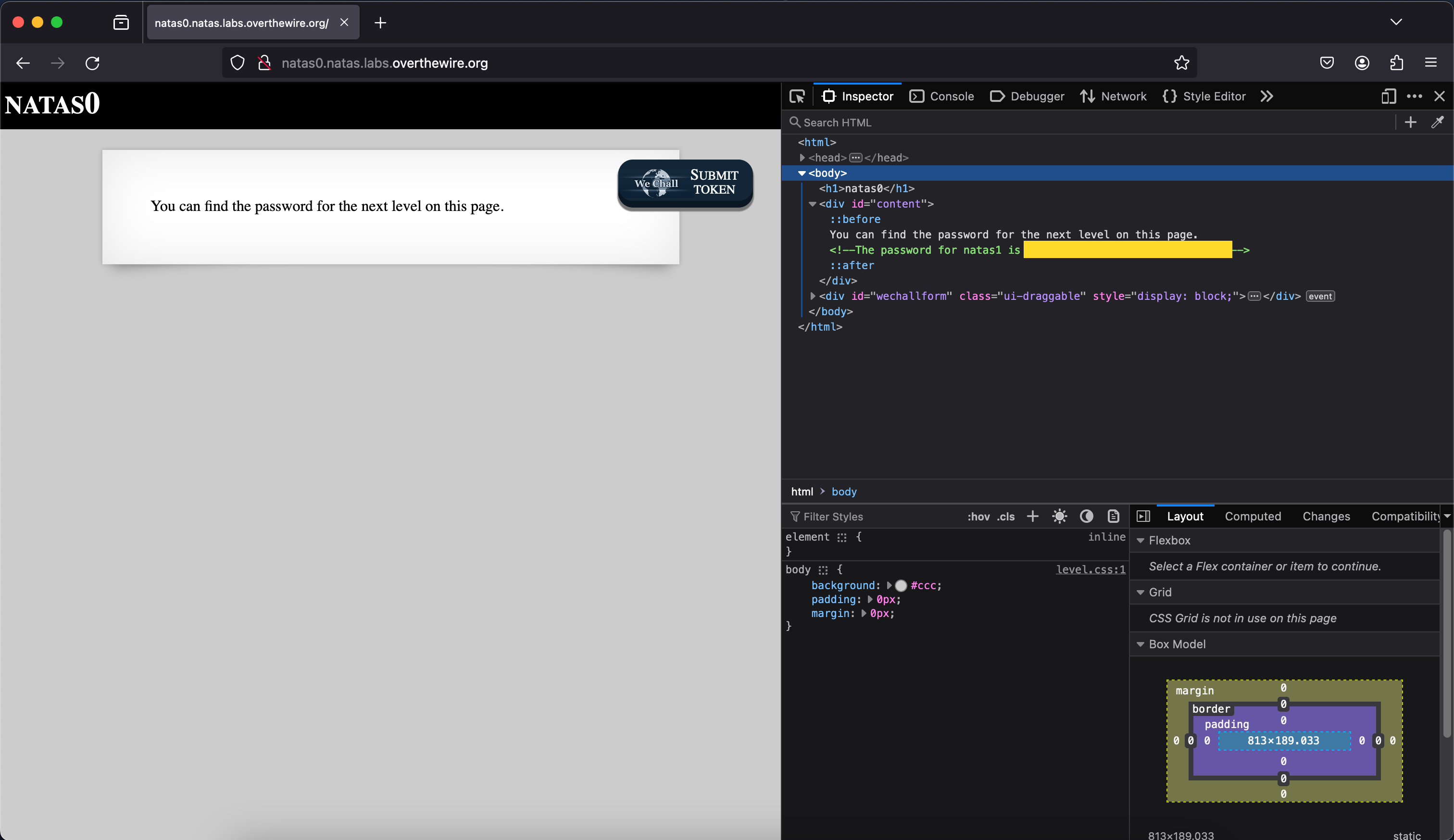
The first two levels are rather trivial. One can simply find the flag
hidden inside the devtools’ inspect element. Right click on the page
and press inspect, or press ctrl + shift + i.
The inspect element tool is used to view what elements a webpage consists of, thus the name. I personally use this tool to debug my CSS and fine-tune the positioning of different elements on the screen.
Level 2
This is where it starts to become more challenging. Upon inspecting the webpage, we see that there is nothing hidden within the comments and elements. Where else can we find clues for where the flag is located?
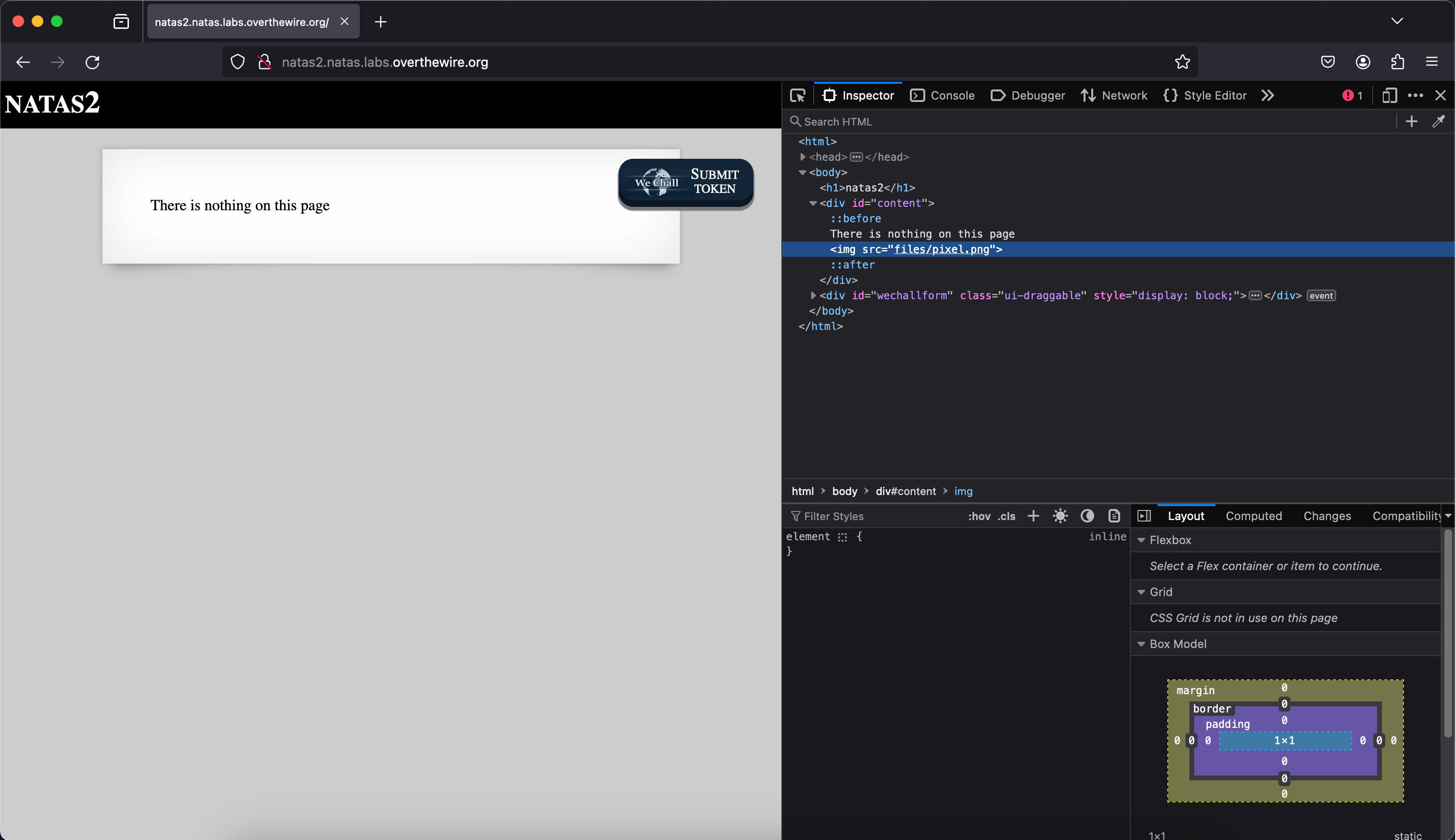
We see that there is a tiny ass 1x1 pixel image loaded on the page. It seems
to be loaded from the /files/ directory. Let’s pay it a visit.
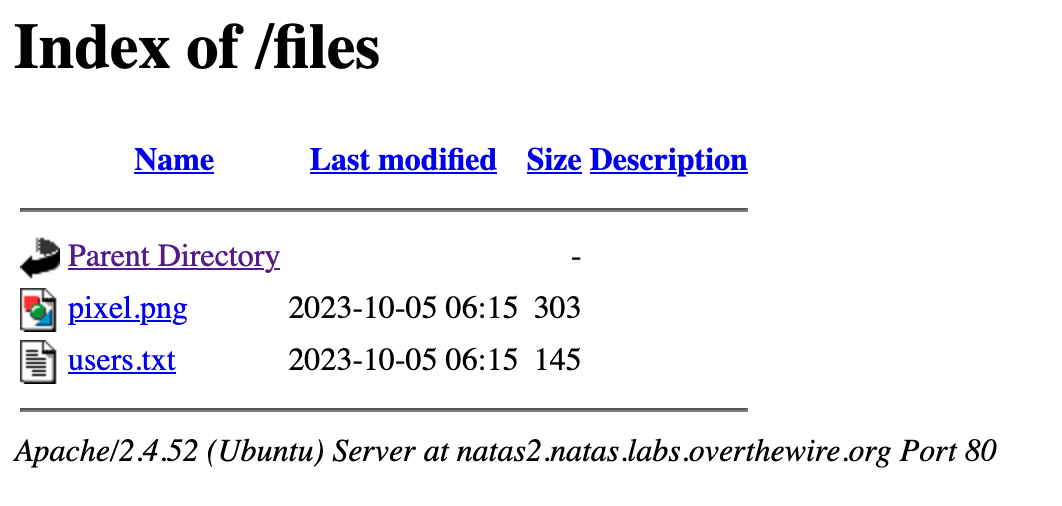
Viola! We see an entry for users.txt, which contains the flag.
Level 2 - Explanation
This file explorer-like interface is called a
directory listing
. The Apache HTTP server has an option to list the directory contents when the
path that leads to a folder instead of a file (i.e. /files instead of
/files/pixel.png) is queried. For this challenge, that option
seems to be enabled, thus leaking the users.txt file.
Back in the days, when networks used to span within school campuses or small geographical areas, people would host different types of content on their computers. Ranging from school notes to pirated movies, people needed a way to share their shit. Thus, directory listing was born so that people could expose their folder on the internet, and everyone can just view their files remotely.
Interlude - Thought Process
When starting out with web pentesting, there is no clear cut way to easily find
these flags. A sane person would not randomly poke around at the source code and
wonder to themselves, “hmm, if I visit /files, would I be able to steal some creds?”.
You have to actively explore each possible point of exploitation and whack till you find something. 90% of the time would be spent going down rabbit holes, but do not get discouraged.
You’ve just got to keep practising these labs, and eventually, you’ll start to become more sensitive to which paths are rabbit holes and which paths are not, and you’ll slowly start to complete these challenges faster and faster.
Ok enough yapping, let’s move on to level 3.
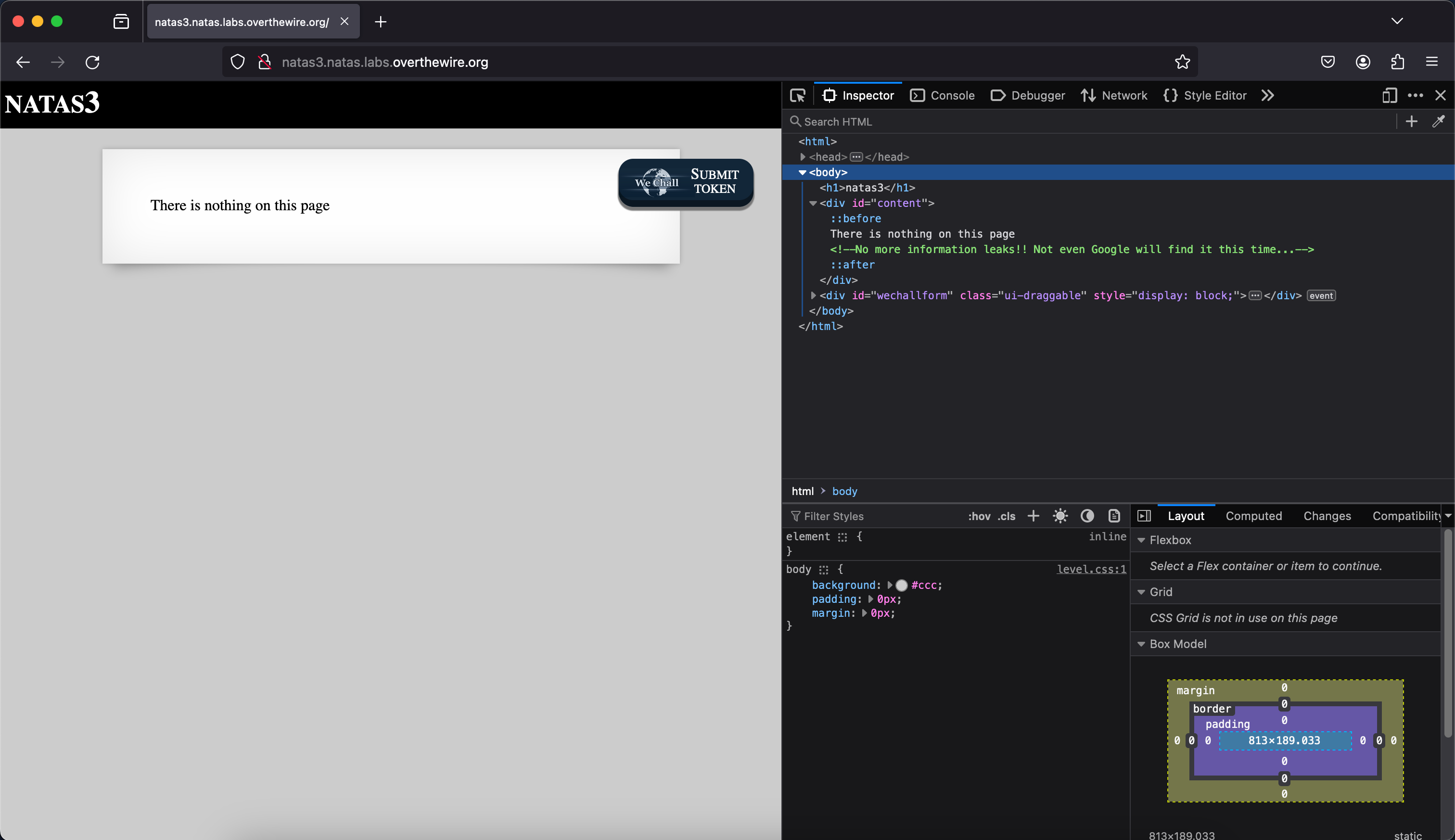
Level 3
Upon inspecting the page, we come across absolutely NOTHING. There is not even a file or folder that we can explore. The only seemingly possible solution to this is to pull out random file paths out of our asses and try it, and you are right. That is EXACTLY what we are going to do.
Level 3 - Robots.txt
First file to try, robots.txt. Why is it called robots.txt, and what does it do?
In simple terms, this file exists to tell robots (or web-scrapers) to stay the fuck away
from certain protected paths. Now you may be confused, it’s just a text file, can’t the robots just
ignore this and proceed to fuck around with those paths? You are absolutely right.
However, there is a small issue. Most web-scraping libraries out there
forces you to obey robots.txt. Hence, if you are unable to create your own web-scraping
library from scratch, you are better off being a good boy/girl and listen to the
rules dictated in robots.txt.
Google has a robots.txt file too, if you wanna see it, you can visit https://google.com/robots.txt.
The structure is simple, it says which User-Agent, or which “browser”, is being blacklisted,
followed by the directories that it is banned from. The wildcard (*) operator is used to denote
all robot browsers/user-agents from accessing it.
User-agent: *
Disallow: /search
This snippet above means that all robots are not allowed to visit https://google.com/search.
User-agent: Twitterbot
Allow: /search
Disallow: /groups
This snippet above means that Twitter should fuck off from https://google.com/groups, but is welcomed
to visit https://google.com/search
Now you may ask, how the FUCK does a robot blacklist help us in solving this challenge? Since this file provides us with a list of blacklisted paths/endpoints for robots, it also “leaks” information about the site. Endpoints which may not otherwise be accessible by clicking links may be revealed here. In this challenge, it is exactly the case.
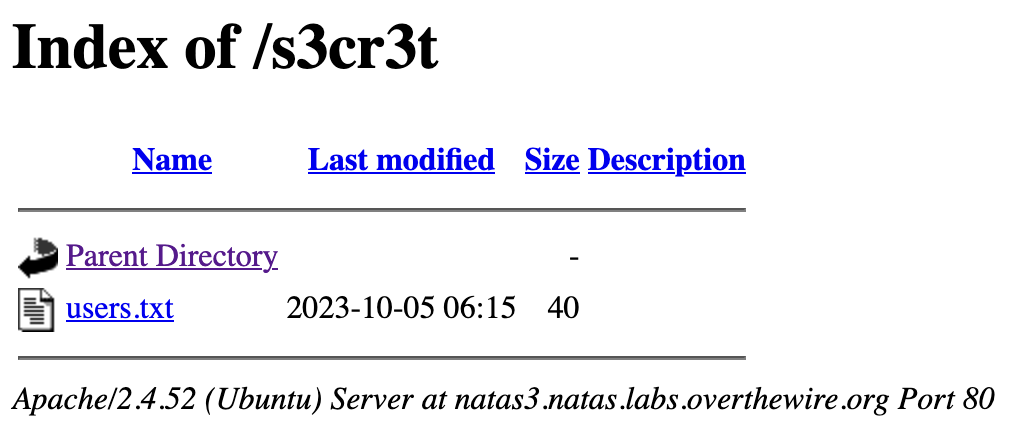
Upon visiting the /robots.txt endpoint, we are told that all bots cannot visit /s3cr3t/.
Let’s put the information given above to good use and try to find this page 😄
Conclusion
Hopefully y’all got something out of this blog post. I am typing this half-drunk at 12am, so do drop me a text if there are any unclear parts or typos and I’d happily fix them.
Cheers and goodnight,
Bowen